


A simple guide to understanding the biggest trap in ML, finding the right balance, and the practical steps to fix your models.
You’ve done it. You’ve spent hours cleaning your data, you’ve chosen a cool algorithm, and you’ve trained your first machine learning model. You check its performance on the data you used for training, and the accuracy is incredible 99%! You feel like a genius.
But then, you show it some new, real-world data. The data it has never seen before. Suddenly, the accuracy plummets to 55%. The model is practically useless.
What happened? Your model wasn't learning; it was lying to you.
This is the most common and frustrating trap that every single person in machine learning falls into. It’s a problem rooted in two fundamental concepts: Overfitting and Underfitting. Understanding and mastering the balance between them is what separates a beginner from a professional.

The "Student Who Memorizes" - A Simple Look at Overfitting
Imagine a student preparing for a big exam. This student doesn't try to understand the concepts. Instead, they get the exact list of 100 questions that will be on the test and memorize the answers perfectly, word for word.
On exam day, if those exact 100 questions appear, the student will get a perfect score: 100%.
But what happens if the teacher changes the questions slightly? Even a small change in wording or numbers will confuse the student. They can't answer because they never learned the underlying principles; they only memorized the specific examples.
This is Overfitting.
In machine learning, an overfitted model is exactly like this student. It learns the training data too well. It doesn't just learn the important patterns and relationships; it also learns the random noise, the irrelevant details, and the quirks specific to that particular dataset.
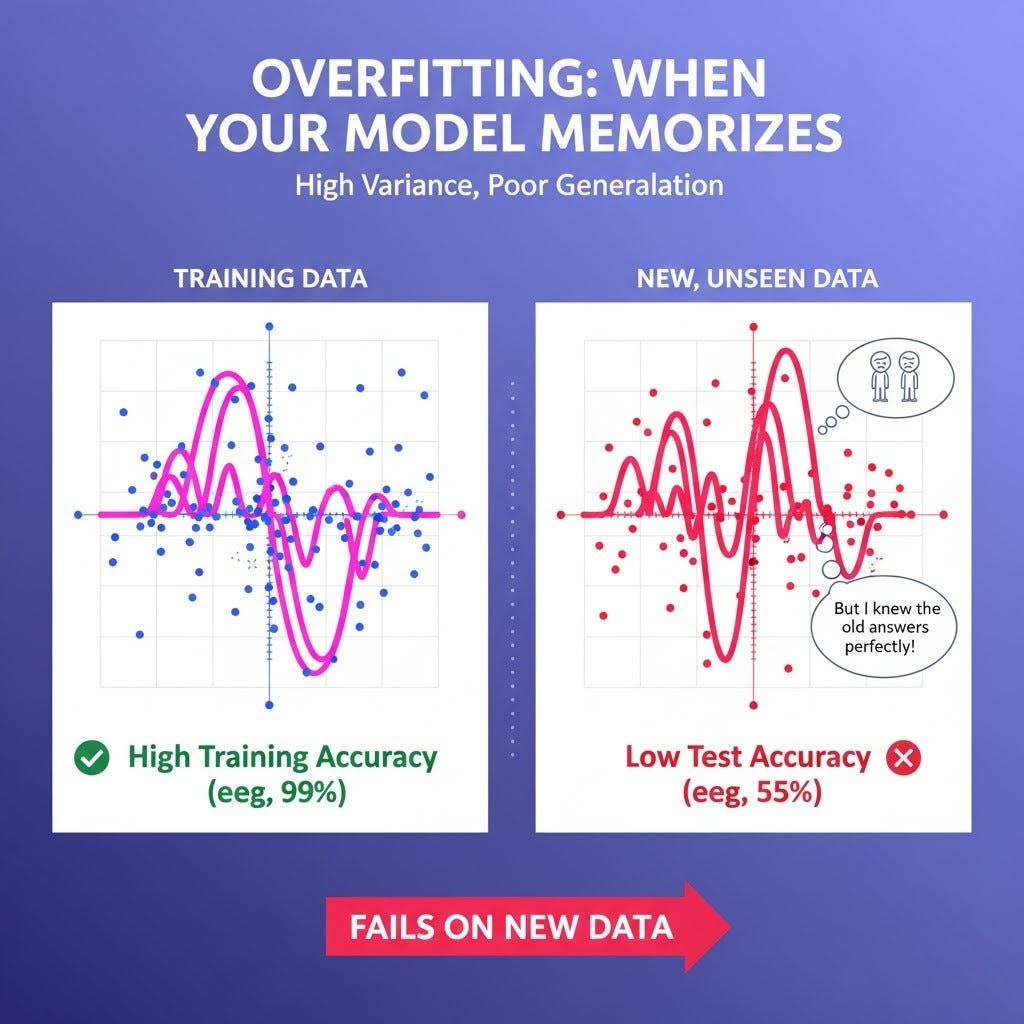
The Symptom: Your model shows very high accuracy on the training data but performs poorly on new, unseen data (like a validation or test set).
The Technical Term: This is a model with High Variance. It's "variable" because its performance changes drastically when the data changes even slightly.
The "Student Who Didn't Study" - Understanding Underfitting
Now, imagine the opposite kind of student. This one didn't study at all. They walk into the exam without even opening the book.
They won't be able to answer the questions they've seen before, and they certainly won't be able to answer any new questions. Their performance will be terrible across the board.
This is Underfitting.
An underfitted model is too simple to capture the underlying structure of the data. It hasn't learned the patterns, and its predictions are inaccurate on both the data it was trained on and new data. It has failed to learn almost anything meaningful.
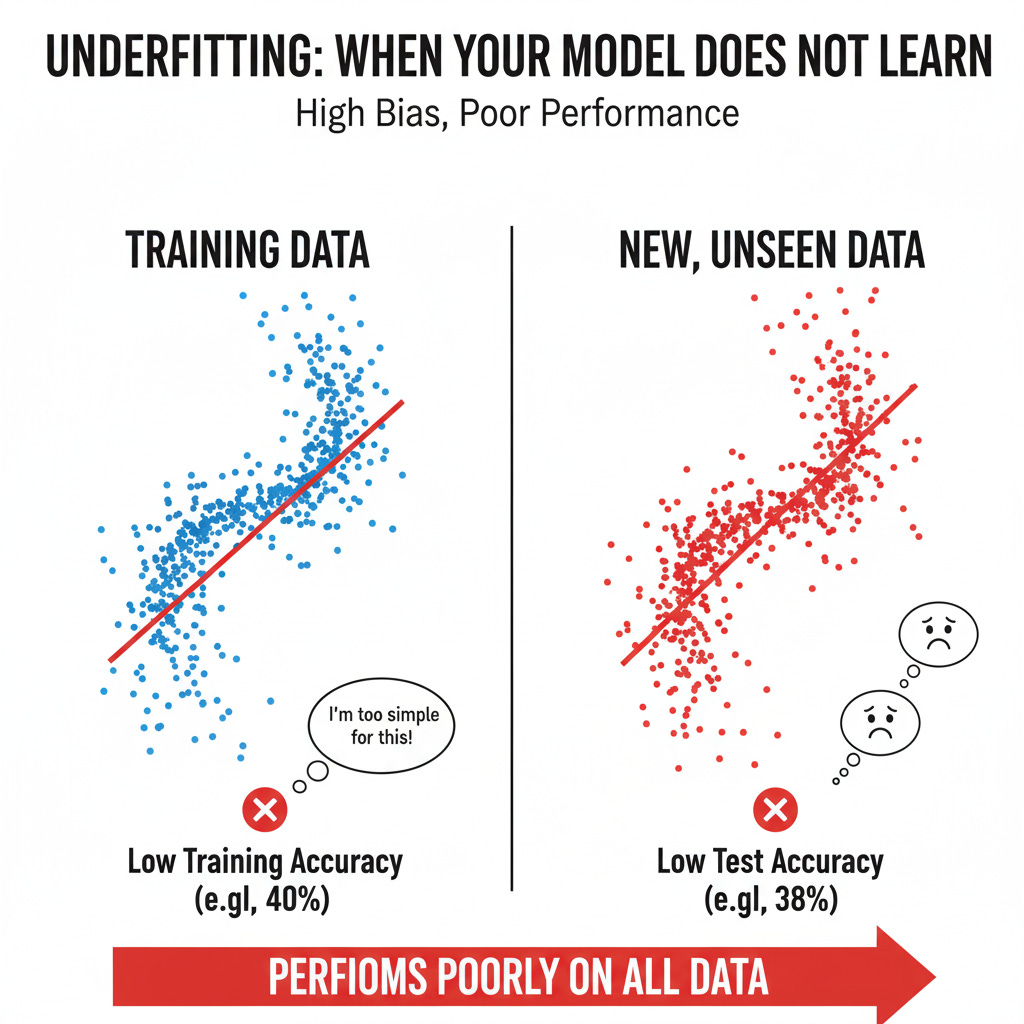
The Symptom: Your model has poor accuracy on the training data and on the test data.
The Technical Term: This is a model with High Bias. "Bias" refers to the simplifying assumptions made by a model. When the assumptions are too simple (e.g., assuming a complex, curvy relationship is just a straight line), the model is biased and fails to capture reality.
The Great Balancing Act: The Bias-Variance Tradeoff
The core challenge of machine learning is not just avoiding these two problems, but finding the perfect balance between them. This is known as the Bias-Variance Tradeoff.
Think of it like a seesaw:
On one side, you have Bias (simplicity).
On the other side, you have Variance (complexity).
If you make your model more complex to reduce its bias (to stop underfitting), you risk increasing its variance (and starting to overfit).
If you make your model simpler to reduce its variance (to stop overfitting), you risk increasing its bias (and starting to underfit).
You can't have both at zero. Your job as a machine learning practitioner is not to eliminate them, but to find the "sweet spot"—that perfect point of balance where the model generalizes well to new data.
Your Toolkit: Practical Solutions to Fix Your Models
So, how do you find this sweet spot? It's not about magic; it's about having the right tools and techniques.
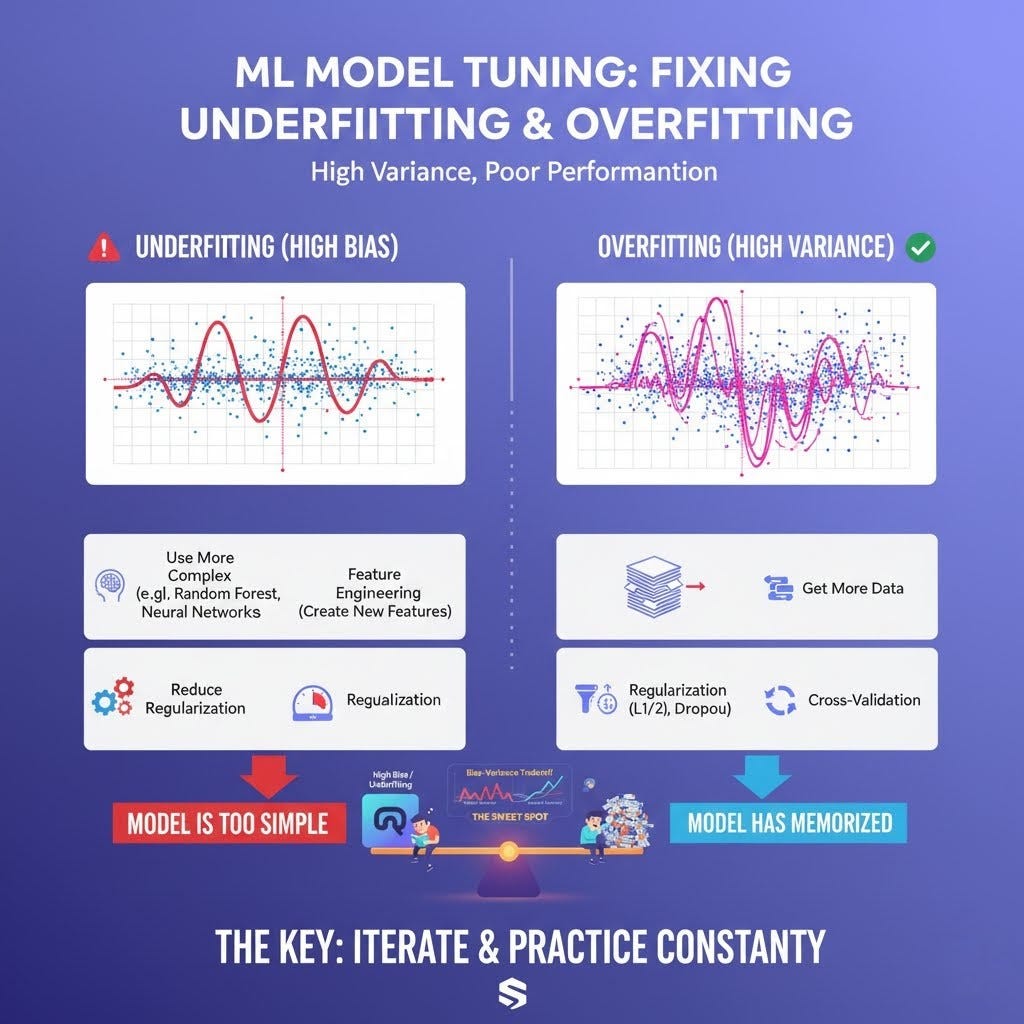
How to Fix Overfitting (High Variance):
When your model is memorizing, you need to help it generalize.
Get More Training Data: This is the most powerful solution. Giving the "memorizing student" more and more examples of different questions makes it harder for them to just memorize. They are forced to start learning the underlying concepts to keep up.
Simplify the Model: If you are using a very complex model (like a deep neural network or a very large decision tree), try a simpler one. Sometimes, a simple Linear Regression is better than a complex model that overfits.
Use Regularization (L1 & L2): This is a very popular and powerful technique. Regularization adds a "penalty" to the model for being too complex. It forces the model to keep its parameters small, which in turn makes it simpler and less likely to chase after noise in the data. Think of it as telling the model, "Try to find a good solution, but keep it simple!"
Use Dropout (for Neural Networks): Dropout is a technique specific to neural networks. During training, it randomly "switches off" a fraction of neurons. This prevents any single neuron from becoming too specialized on certain features and forces the network to learn more robust patterns.
Use Cross-Validation: Techniques like k-fold cross-validation give you a much more reliable estimate of how your model will perform on unseen data. It helps you detect overfitting more effectively than a simple train-test split.
How to Fix Underfitting (High Bias):
When your model isn't learning enough, you need to give it more power and better information.
Use a More Complex Model: If a simple model is underfitting, it might not have the capacity to learn the patterns. Switch from a linear model to a non-linear one like a Polynomial Regression, a Support Vector Machine, or a Random Forest.
Feature Engineering: This is an art. Maybe your model doesn't have the right information to make good predictions. You can create new, more meaningful features from your existing data. For example, if you have height and weight, you could create a Body Mass Index (BMI) feature, which might be more predictive.
Reduce Regularization: If you are applying a strong penalty for complexity, you might be "dumbing down" your model too much. Try reducing the amount of regularization to allow the model to learn more complex patterns.
The Real Secret: Practice Is Everything
You can read a hundred articles about this, but you will only truly understand the Bias-Variance tradeoff by getting your hands dirty. Theory gives you a map, but practice teaches you how to navigate the terrain.
Here’s how you can practice effectively:
Build and Break Models: Go to a platform like Kaggle. Pick a dataset. Intentionally build a model that overfits—use a massively complex algorithm on a small amount of data. Watch what happens. Then, build one that underfits—use a very simple model on complex data.
Experiment with Solutions: Take your overfitted model and try applying the solutions one by one. Add regularization and see how it affects the result. If you have more data, add it and watch the validation accuracy improve.
Visualize Your Results: Plot learning curves. These are graphs that show your model's performance on the training data versus the validation data over time. They provide a clear visual diagnosis:
If the training and validation scores are both low, it’s underfitting.
If the training score is high and the validation score is low (and there's a large gap between them), it’s overfitting.
Final Thoughts
The constant battle with overfitting and underfitting isn't a sign that you're doing something wrong. It is the very essence of building a good machine learning model.
Your model will almost always try to lie to you by showing you a flattering but misleading training score. Your job is to be the skeptic—to test it, to challenge it, and to use these tools to guide it toward a real, generalized understanding of the world.
Mastering this balance is a journey, but it’s the journey that turns you from someone who can just model.fit() into a true machine learning practitioner.

++ Good Post. Also, start here : 500+ LLM, RAG, ML System Design Case Studies, 300+ Implemented Projects, Research papers in detail
https://open.substack.com/pub/naina0405/p/most-asked-ml-system-design-case-ada?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false